Scaling Robot Supervision to Hundreds of Hours with RoboTurk
Robotic Manipulation Dataset through Human Reasoning and Dexterity

Real Robot Paper Get the Real Robot Dataset
We demonstrate applying the RoboTurk platform to real robots and show the possibility of scaling to hundreds of hours of data using few real robots. Previous works with large scale robotic manipulation datasets have had a low signal-to-noise ratio as they have been collected through self-supervised methods. We collect the largest dataset for robotic manipulation through remote teloperation. Over the course of 1 week using 54 operators, we collected 111 hours of robotic manipulation data on 3 challenging manipulation tasks that require dexterous control and human planning.
Using the RoboTurk platform, we were able to collect the largest dataset for robotic manipulation via teleoperation to date using only 3 Sawyer robot arms. Demonstrating diversity, dexterity, and scale. When compared to previous works, we collect between 8x-100x the amount of robot hours with episodes lasting 3x-40x longer which shows the diversity of demonstrations as well as task difficulty.
* indicates extrapolated values from the information reported by the dataset
Users were able to rapidly adapt to the control interface and successfully complete all the tasks with many seeing their fist task completion on their very first try. This shows the benefit to using humans for data collection over self-supervised methods which might be incapable of solving complext tasks.


People can also teleoperate from anywhere around the world. We have successfully teleoperated from the top of moutanins and from three different countries around the world. This specific video was shot in Macau when the robot was located in our lab in California.
The tasks that were chosen are difficult and lend themselves to producing a highly diverse dataset that admits many different approaches to solving the task. Below are random samples from the dataset for each task.
We also observe the use of many different emergent strategies for solving the tasks. Below we present some of them from the tower creation task.

An 'inverted cone'

Flipping the bottom bowl

Alternating cups and bowls

Using three cups to make a stable base
The tasks selected also require a high degree of dexterity in the types of interactions and grasps required to complete the tasks. Many times a simple top down grasp would not be capable of solving the task. We observed many interesting approaches to dexterity, and even creative uses of the objects themselves.
Stuffing objects into the goal location
Creative object use
Move an object for a better grasp
Flipping objects for a better grasp
Clever grasp for placement
Approach object at an angle
We use the RoboTurk platform to collect a large dataset on three difficult manipulation tasks that involve planning, vision, and dexterity. All three of these tasks require high-level reasoning (the "what") on the part of the demonstrator and low-level dexterity (the "how") making human demonstrations necessary.
The "laundry layout" task
In the "laundry layout" task, users are to use the robot to efficiently flatten the cloth or other fabric object. This task requires reasoning to identify how best to flatten the object as well as dexterous manipulation behaviors like pushing, pulling, and pick-and-place.
The "tower creation" task
In the "tower creation" task, users are to use the robot to stack common kitchen items into the tallest tower that is possible. This task requires reasoning to construct a tower that is both tall and stable as well as dexterous manipulation behaviors like stacking.
The "object search" task
In the "object search" task, users are to search in a bin for three objects of the same class without discarding distractor objects. This task requires reasoning to search effectively and identify target objects as well as dexterous manipulation behaviors like picking and fitting.

The dataset collected contains information from a variety of different sensors and data streams. In particular, we collect the following streams:
As users interact with the system longer, the quality of their demonstrations generally increases. Users learn to more efficiently complete the object search and laundry layout tasks, which is exemplified by decreased time to completion. Total amount of effort (as measured by amount of translational movement at the end effector) does not change significantly as experience increases. This shows that users translate the end effector at the same rate. However, users learn to become more dexterous with their manipulation by increasingly utilizing changes in orientation as experience increases.
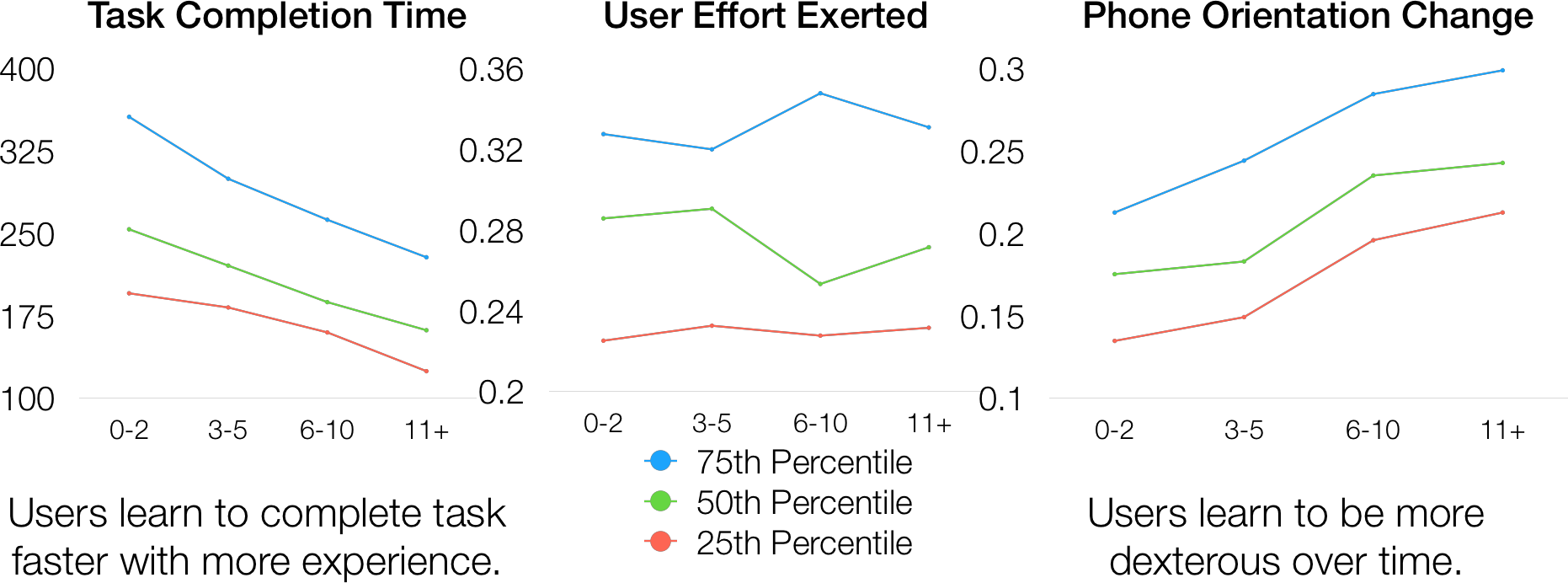
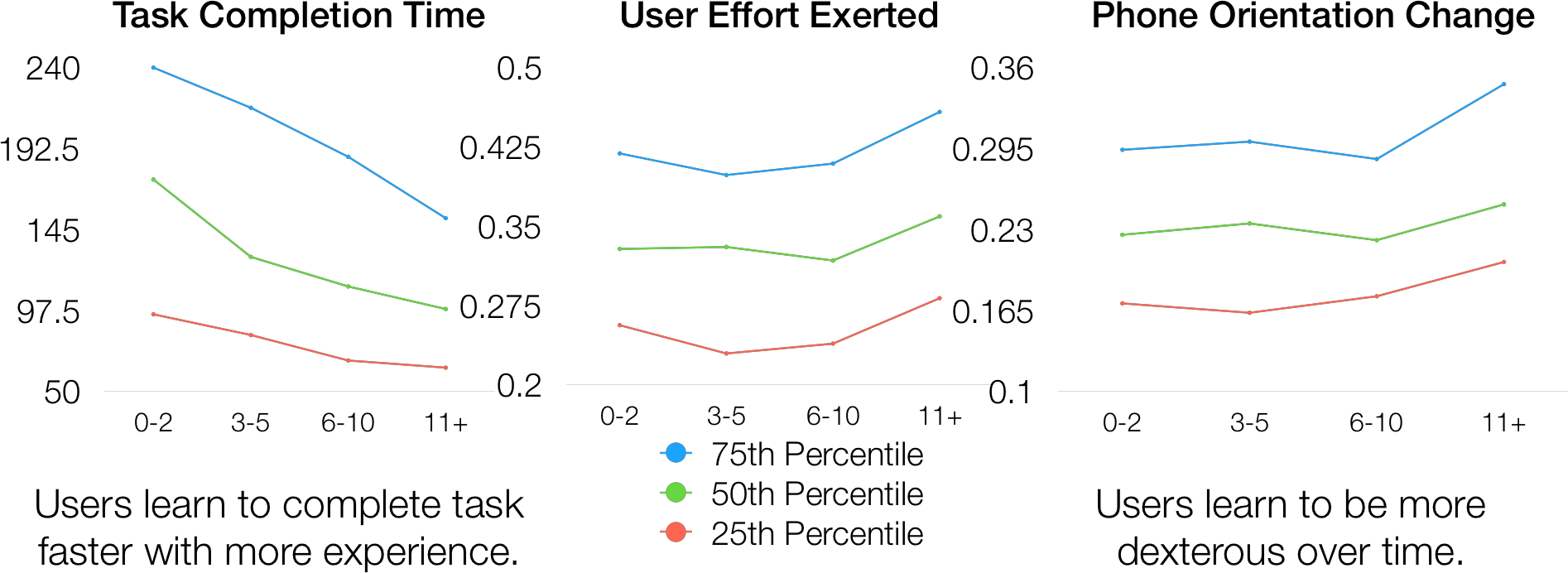
A majority (60.8%) of users felt comfortable using the system within 15 minutes with 96% comfortable within an hour. Users were asked to self-evaluate their performance on each task using the NASA TLX survey which gives a measure of task difficulty (higher total corresponds to increased difficulty). Note that * indicates lower is better.
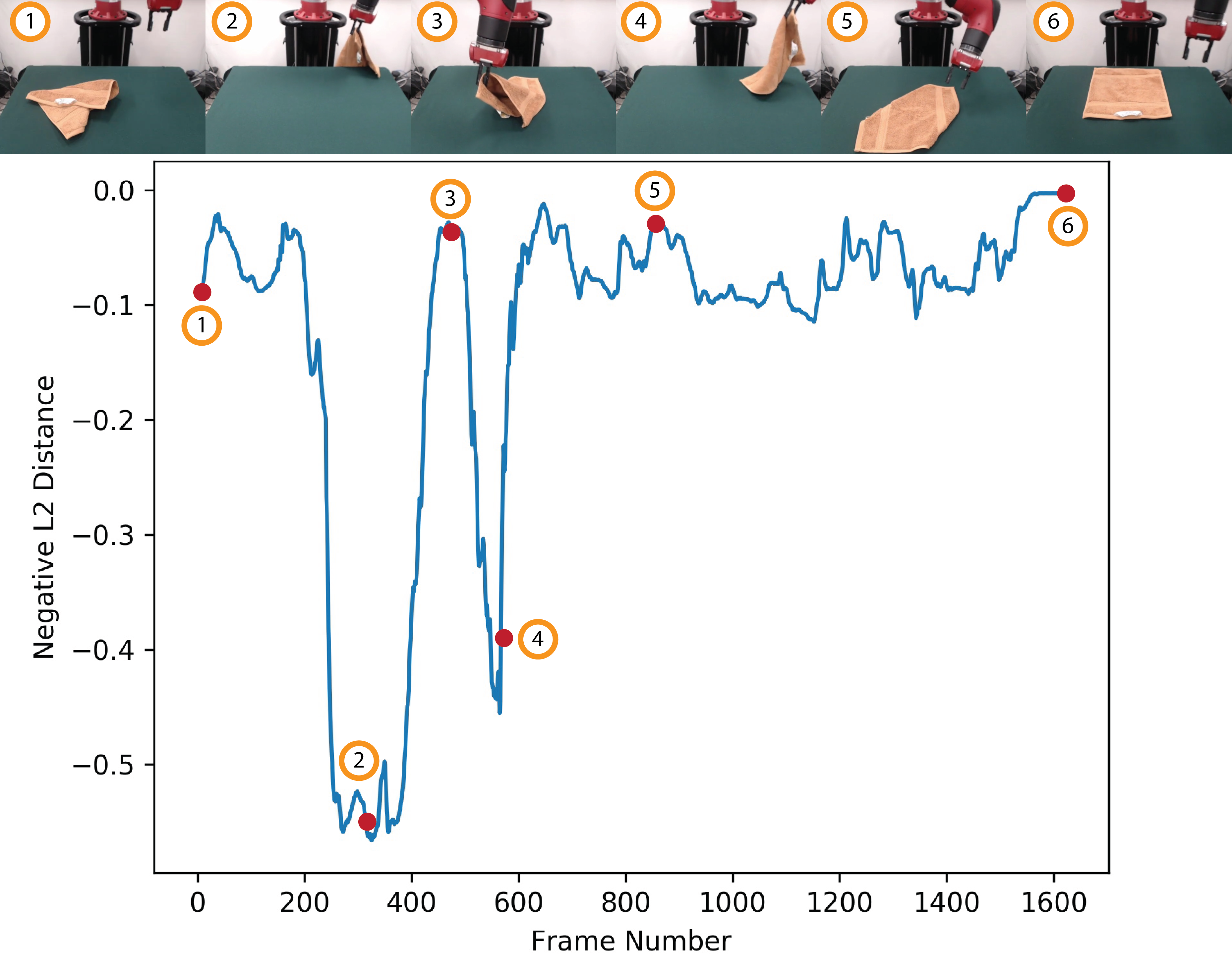
To illustrate the utility of our dataset, we examine the possibility of inferring a reward signal from the collected demonstrations. These methods show that the dataset is useful for imitation learning.
Specifically, we use a modified version of Time Contrastive Networks to efficiently learn an embeding space that is meaningful across long time horizons where a reward signal can be inferred by negative distances in the embedding space. The circled numbers show correspondences between points on the curve and images from the trajectory.
We additionally show that the colected data can be used with straightforward imitation learning methods. Specifically, we demonstrate successful utilization of Behavioral Cloning on simplified instances of the Laundry Layout task where the agent needs only one unfolding step to solve the environment. See the trained (sped up 3x) policy below.
